

The Problem with Searching Only by Similarity
How human memory reveals what RAG still misses: the power of retrieving what belongs together, not just what looks similar.


You hear the first few notes of a song.
Not the chorus. Not even the lyrics. Just a few notes.
And suddenly, something opens.
You remember the singer. Then maybe the first time you heard it. Maybe the person who showed it to you. Maybe a summer, a city, a car ride, a room, or a version of yourself you had almost forgotten. The cue is small, but what comes back is not small at all.
This is one of the strange and beautiful things about memory. We do not always retrieve memories by searching for the most similar thing. We retrieve through association.
A fragment can bring back a whole episode.
A smell can bring back a house.
A song can bring back a person.
A place can bring back a period of your life.
And often, the things that come back are not “similar” in any simple sense. A melody is not semantically similar to a person. A restaurant is not semantically similar to a conversation. A rainy street is not semantically similar to a decision you made there years ago. Yet in memory, they belong together.
They were connected by experience.
That distinction matters more than we realize, especially now that retrieval has become one of the central mechanisms behind modern AI systems.
The usual way we retrieve
A lot of AI retrieval today works through similarity.
A question is turned into a mathematical representation, usually an embedding. Documents, paragraphs, or chunks of text are also turned into embeddings. The system then searches for the stored pieces that are closest to the query in that embedding space.
This is powerful. It is one of the reasons retrieval-augmented generation became so useful. Instead of asking a language model to rely only on what it already has in its parameters, we can give it external information at the moment it needs to answer.
Ask a question, retrieve relevant passages, pass them to the model, generate an answer.
For many cases, this works very well.
If I ask, “What is the capital of Cyprus?” I want the system to retrieve text about Cyprus, capitals, and Nicosia. Similarity is enough.
But not every question is like that.
Some questions are not asking for the nearest paragraph. They are asking for the surrounding context.
They ask for history, not just facts.
They ask for consequences, not just definitions.
They ask for the situation around the answer.
And this is where searching only by similarity starts to feel too narrow.
Similarity is not the same as relevance
The problem is not that similarity is useless. The problem is that similarity quietly becomes a substitute for relevance.
But relevance is larger than similarity.
Two things can be semantically similar and not meaningfully connected.
Two other things can be deeply connected and not semantically similar at all.
Imagine you are asking an AI assistant why a particular decision was made in a company. A similarity-based retriever may find the document where the decision is stated. That is useful. But the real answer may depend on the meeting where the disagreement started, the earlier customer complaint, the budget pressure, the person who objected, and the later email that changed the interpretation.
Those pieces may not all look similar to the original query. Some may not contain the same keywords. Some may not even use the same vocabulary. But they are part of the same story.
The same thing happens in scientific research. A paper may make a claim. The most similar documents may be papers making similar claims. But to understand the claim properly, we may also need the criticism, the failed replication, the dataset limitation, the later correction, or the older theory it quietly depends on.
Again, these are not always the nearest neighbors in embedding space.
They are connected because they form a chain of meaning, evidence, context, and consequence.
Similarity gives us the nearest text. Association can give us the wider situation.
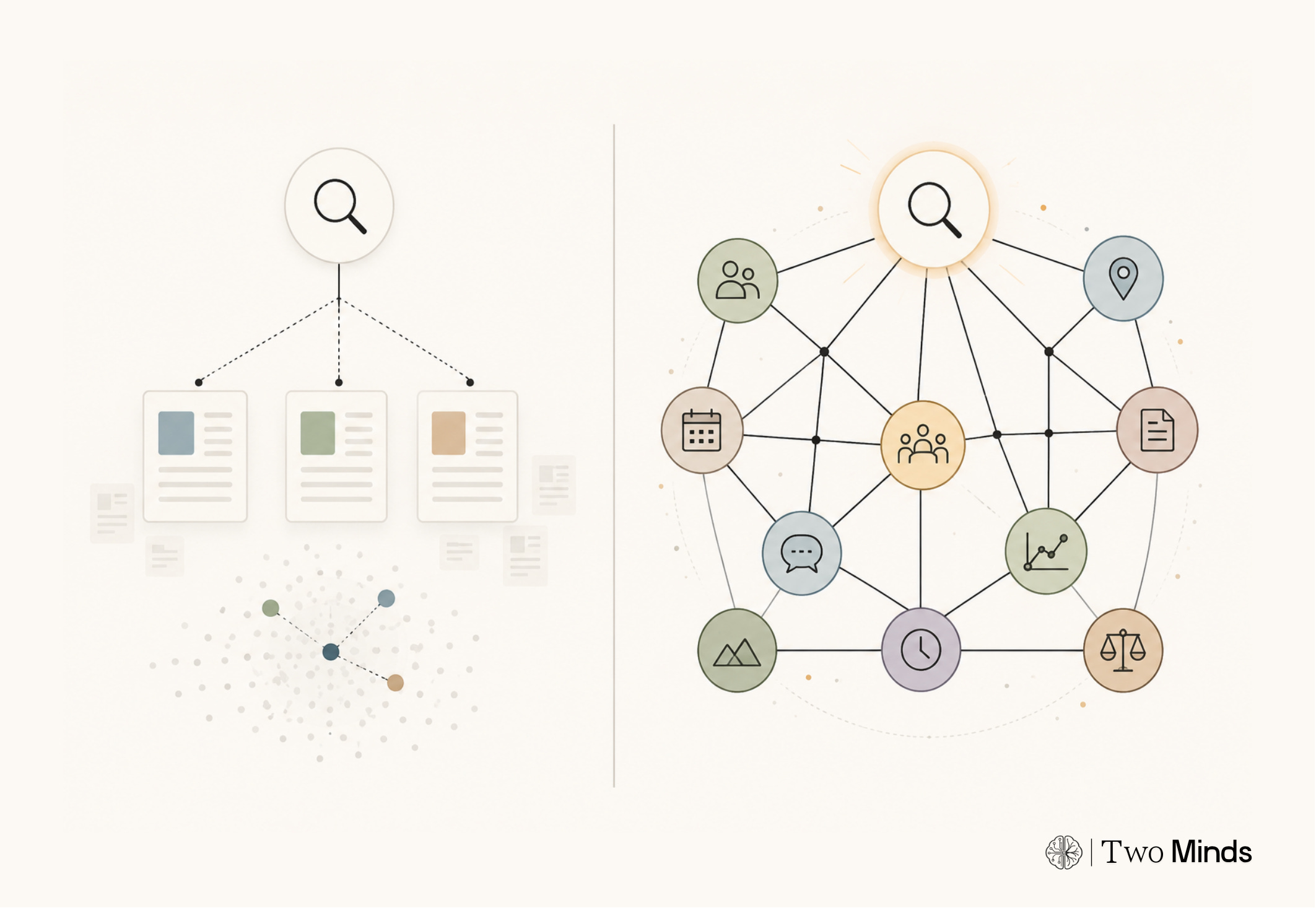
How memory does something different
Human memory is not a database. It is not a search engine. It is not a vector store with feelings added on top.
But it gives us a useful analogy.
One important idea from neuroscience is that the brain can recover a fuller memory from a partial cue. This is often discussed through the idea of pattern completion. You do not need the entire memory to retrieve it. A fragment can be enough.
A few notes can bring back the song.
A face can bring back a name.
A smell can bring back a place.
A phrase can bring back a conversation.
The point is not that the brain retrieves a paragraph that is similar to the cue. The point is that the cue reactivates a larger pattern that was stored together.
This is especially important for episodic memory, the kind of memory that has the shape of an experience. An episode is not one isolated fact. It is a binding of many elements: who was there, where it happened, what was said, what came before, what came after, how it felt, and why it mattered.
When we remember an event, we often do not retrieve one clean sentence. We reconstruct a connected scene.
That is much closer to what many AI systems need when they answer complex questions.
Not just: “Find the most similar chunk.”
But: “Recover the relevant episode.”
Pattern completion and pattern separation
There is another important detail.
Memory does not only connect things. It also separates them.
If every similar experience blended into every other similar experience, memory would be useless. You need to remember that two restaurants were different, that two meetings had different outcomes, that two people said similar things for different reasons.
This is where the idea of pattern separation becomes useful.
Pattern completion helps a partial cue bring back a larger memory.
Pattern separation helps similar memories remain distinct.
Good retrieval needs both.
If a system only completes patterns, it may over-connect everything. It may take one cue and pull in too much. The answer becomes vague, noisy, or falsely coherent.

If a system only separates patterns, it may retrieve isolated facts without context. The answer becomes narrow, brittle, and incomplete.
The interesting challenge is the balance.
A better retrieval system should be able to say:
“This cue belongs to this larger context.”
But also:
“This similar-looking context is actually a different case.”
That is what makes human memory feel rich rather than merely broad. It can connect, but it can also discriminate.
Spreading activation: when one memory wakes up another
Another useful idea is spreading activation.
The basic intuition is simple: activating one concept can activate nearby concepts through a network of associations. Think of touching one node in a web and watching the movement travel through the threads.
If I say “Paris”, you may think of France, the Eiffel Tower, a trip, a film, a person, a restaurant, or a song. Which one comes to mind depends on your own history of associations.
For one person, Paris means architecture.
For another, it means heartbreak.
For another, it means a conference.
For another, it means the airport where they missed a flight.
The word is the same. The associations are different.
This is the crucial point: associative memory is shaped by experience.
It is not only about the dictionary meaning of a word. It is about what has repeatedly appeared together, what mattered, what was emotionally marked, what came before and after, and what links were strengthened over time.
That is a very different model of retrieval.
A similarity system asks: what is close to this query?
An associative system asks: once this cue is active, what else should become active because of how the world has connected these things before?
Why this matters for AI agents
This becomes even more important in agentic AI.
A simple chatbot can sometimes get away with retrieving a few relevant passages. An agent cannot.
An agent has goals. It takes actions. It uses tools. It observes results. It works across time. It may need to remember what happened yesterday, what failed last week, which user preference was implied rather than stated, which file was connected to which task, and which decision changed the plan.
For an agent, memory is not just storage. Memory is part of behavior.
If an agent only retrieves by semantic similarity, it may find the text that looks closest to the current request while missing the context that actually matters.
It may retrieve the latest instruction, but not the reason behind it.
It may retrieve the document, but not the correction that came later.
It may retrieve the task, but not the failed attempt that should change how it tries again.
It may retrieve the user preference, but not the situation in which that preference was formed.
This is why associative retrieval matters. Agents need memory that is not only searchable, but connected.
They need to recover trails of action, evidence, correction, and consequence.
They need to know not only what was said, but what it was linked to.
The world does not arrive as isolated chunks
There is also a deeper reason this matters.
The world does not come to us as neatly separated text chunks.
Information arrives as streams. Conversations, emails, documents, meetings, search results, code changes, user feedback, errors, revisions, and decisions all unfold over time.
Similarity search often treats memory as a pile of retrievable fragments.
But experience is not a pile. It has structure.
Things happen before and after other things. Some details repeat. Some links are confirmed. Some fade. Some become important only later.
A sentence may not look important when it first appears. But after three later events, it may become the key to understanding the whole situation.
This is something human memory does all the time. We reinterpret old memories in light of new ones. We strengthen some associations because they keep recurring. We let others weaken because they stop mattering.
A good memory system should not only store information. It should allow relationships between pieces of information to change as new evidence arrives.
That is very different from simply embedding a chunk once and leaving it there.
What associative retrieval could look like
An associative retrieval system would not replace similarity search. It would extend it. Similarity could still be the first step. It is often the easiest way to find an entry point. But after finding the entry point, the system could ask a second set of questions:
What appeared with this information?
What happened before and after it?
Which people, objects, files, claims, or decisions were connected to it?
Which links were repeated across time?
Which associations were strong, and which were weak?
Which related memories should be retrieved together?
Which similar-looking memories should be kept separate?
In this view, retrieval becomes less like searching a library catalogue and more like following a trail.
The query provides a cue.
The cue activates a memory.
The memory activates its context.
The context helps the model answer with a fuller picture.
This is not about making retrieval more poetic. It is about making it more useful.
A system that retrieves associatively may be better at answering questions that require background, continuity, multi-step context, or hidden connections. It may produce answers that are less shallow because it has access not only to matching text, but to the structure around that text.
A simple example
Imagine asking an AI assistant:
“Why did we decide not to launch this feature?”
A similarity-based system may retrieve the product document with the final decision: “Launch postponed due to technical risk.”
That is not wrong.
But an associative system might retrieve more:
The bug report that first raised the risk.
The meeting where engineering objected.
The customer interview that made the feature less urgent.
The later discussion where the team chose a smaller version.
The person responsible for revisiting it next quarter.
Now the answer changes.
Not because the first retrieval was false, but because it was incomplete.
The better answer is not only:
“The launch was postponed due to technical risk.”
It is:
“The launch was postponed because the technical risk was raised in the bug report, reinforced during the engineering review, and became less urgent after the customer interviews suggested that a smaller version would solve the immediate need. The team decided to revisit the full version next quarter.”
That is the difference between retrieving a sentence and retrieving a situation.
The danger of isolated relevance
The danger of similarity-only retrieval is that it can create the illusion of grounding.
The model receives retrieved context. The answer looks supported. The system appears to have checked external knowledge.
But if the retrieved context is too narrow, the answer may still miss the real issue.
It can be locally grounded and globally wrong.
This is especially dangerous in domains where context changes the meaning of information: law, medicine, science, finance, software engineering, policy, and long-running personal or organizational work.
In those domains, the right answer often depends on relationships.
What superseded what?
What exception applies?
What evidence supports this?
What was contradicted later?
Which case is similar, but not the same?
Who said this, and in what context?
Similarity helps find relevant material. But association helps understand why it matters.
Beyond the nearest neighbor
The future of retrieval should not be a choice between vectors and graphs, similarity and memory, search and reasoning.
It will probably need all of them.
Embeddings are useful because they give us flexible semantic search. Graphs are useful because they preserve relationships. Time is useful because it tells us how information unfolds. Repetition is useful because it tells us which links are stable. Decay is useful because not every connection should remain equally important forever.
The bigger shift is conceptual.
We should stop thinking of retrieval as only the act of finding matching text.
Retrieval can also be the act of reactivating a meaningful context.
That context may include similar documents, but it may also include associated events, repeated evidence, earlier causes, later consequences, and neighboring perspectives.
This is closer to how memory works.
Not perfectly. Not biologically. Not romantically.
But usefully.
The real question
When we ask an AI system a question, we often assume the hard part is generating the answer.
But sometimes the harder part is knowing what should be brought into view before the answer is generated.
What counts as relevant?
The nearest sentence?
The most similar paragraph?
The most recent document?
The strongest association?
The episode around the fact?
The chain that explains how we got here?
Similarity gives us one answer to that question. It is an important answer, but it is not enough.
Human memory suggests another possibility.
Sometimes, the right memory is not the one that looks most like the question.
It is the one that belongs to the same story.
Memory Is Bigger Than Similarity
A few notes of a song can bring back a whole world.
That is not because the world is similar to the notes. It is because memory is associative. It binds things together, separates similar experiences, completes partial patterns, and lets one cue awaken a wider network.
AI retrieval is still young. Much of it is very good at finding nearby text. But as AI systems become more agentic, more personal, and more involved in long-running work, nearby text will not always be enough.
We will need retrieval systems that can search not only by what things mean in isolation, but by how they were connected in experience.
The problem with searching only by similarity is not that similarity fails.
It is that memory is bigger than similarity.
And retrieval should be too.
Further reading
Karpukhin et al., Dense Passage Retrieval for Open-Domain Question Answering
A foundational paper for dense retrieval, showing how learned passage and query embeddings can retrieve relevant contexts for open-domain question answering.Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
The classic RAG paper, useful for understanding how language models can combine parametric knowledge with retrieved external memory.Rolls, The Mechanisms for Pattern Completion and Pattern Separation in the Hippocampus
A useful neuroscience reference for understanding how partial cues can recover fuller stored patterns, and why memory also needs separation between similar experiences.Yassa and Stark, Pattern Separation in the Hippocampus
A clear reference on how the hippocampus helps distinguish overlapping memories while still supporting retrieval from partial cues.Horner et al., Evidence for Holistic Episodic Recollection via Hippocampal Pattern Completion
A strong paper for the idea that episodic memory binds elements of an event together, allowing one part of an event to bring back the rest.Collins and Loftus, A Spreading-Activation Theory of Semantic Processing
The classic cognitive psychology paper behind the idea that activating one concept can spread through a network of related concepts.Edge et al., From Local to Global: A Graph RAG Approach to Query-Focused Summarization
A modern AI reference showing why retrieval over connected structures can help with broader questions that are not answered well by isolated retrieved chunks.
Andreas, I come at this from a completely different direction, I write about cognitive atrophy in organizations and what AI reveals about how humans think, and this piece landed like a mirror held up at an unexpected angle.
What struck me most is the inversion at the heart of your argument. You're describing a future where AI retrieval needs to become more associative, more episodic, more capable of recovering a situation rather than just matching text. And I keep writing about how humans are losing exactly those capacities at scale: the ability to hold context, trace consequence, recover the chain of meaning behind a decision rather than just the decision itself.
We're engineering machines toward the cognitive richness we're engineering out of our organizations.
Your "locally grounded, globally wrong" formulation is one of the sharpest descriptions I've read of what I call the expert-without-wisdom failure mode. The answer checks out. The retrieved passage is accurate. But the real situation, the bug report, the objection that was overruled, the correction that came later: is exactly what got lost in the last round of layoffs, or never made it into the documentation, or lived only in the memory of the person who left.
Similarity-only retrieval is not just an AI architecture problem. It's a description of how a lot of institutional thinking already works. Which means your argument about what AI memory needs to become is also, quietly, an argument about what human organizations have already lost.